实现集合
因为集合是不存放重复元素的,所以使用二分搜索树来实现集合很合适。 集合的几个简单方法:
- void add(E) //添加元素,但不能添加重复元素
- void remove(E) //删除元素E
- boolean contains(E) //是否包含元素E
- int getSize() //获得集合的size
- boolean isEmpty() //判断集合是否为空
基于二分搜索树的实现
首先使用二分搜索树做底层实现集合类。二分搜索树的实现代码:https://homxuwang.github.io/2018/07/18/%E4%BA%8C%E5%88%86%E6%90%9C%E7%B4%A2%E6%A0%91/
创建集合接口类Set:
public interface Set<E> {
void add(E e);
void remove(E e);
boolean isEmpty();
boolean containes(E e);
int getSize();
}
然后创建实现集合的类BSTSet:
public class BSTSet<E extends Comparable<E>> implements Set<E> {
private BST<E> bst;
public BSTSet() {
bst = new BST<>();
}
@Override
public void add(E e) {
bst.add(e);
}
@Override
public void remove(E e) {
bst.remove(e);
}
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
@Override
public boolean containes(E e) {
return bst.contains(e);
}
@Override
public int getSize() {
return bst.size();
}
}
其实BSTSet集合类只是简单的调用了其基础类BST类的方法。就可以实现集合类的各个功能。
基于链表的实现
链表结构的实现
首先链表的实现代码:
public class LinkedList<E> {
private class Node{
public E e;
public Node next;
/**
* 构造函数
* @param e
* @param next
*/
public Node(E e,Node next){
this.e = e;
this.next = next;
}
public Node(E e){
this(e,null);
}
public Node(){
this(null,null);
}
@Override
public String toString(){
return e.toString();
}
}
private Node dummyHead;
private int size;
public LinkedList(){
dummyHead = new Node();
size = 0;
}
//返回链表中的元素个数
public int getSize(){
return size;
}
//返回链表是否为空
public boolean isEmpty(){
return size == 0;
}
//在链表头添加新的元素e
public void addFirst(E e){
// Node node = new Node(e);
// node.next = head;
// head = node;
//和上面三行相等
add(0,e);
}
//在链表末尾添加新的元素e
public void addLast(E e){
add(size,e);
}
//在中间位置插入新的元素e
public void add(int index,E e){
if(index < 0 || index > size ){
throw new IllegalArgumentException("illegal index");
}
Node prev = dummyHead;
for(int i = 0 ; i < index ; i++){
prev = prev.next;
}
Node node = new Node(e);
node.next = prev.next;
prev.next = node;
size ++;
}
//获得链表中index位置的元素
public E get(int index){
if(index < 0 || index >= size ){
throw new IllegalArgumentException("Get failed.Illegal index.");
}
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i++){
cur = cur.next;
}
return cur.e;
}
//获得链表的第一个元素
public E getFirst(){
return get(0);
}
//获得链表的最后一个元素
public E getLast(){
return get(size - 1);
}
//修改链表index位置的元素为e
public void set(int index,E e){
if(index < 0 || index >= size ){
throw new IllegalArgumentException("Set failed.Illegal index.");
}
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i++ ){
cur = cur.next;
}
cur.e = e;
}
//检查链表中是否有元素e
public boolean contains(E e){
Node cur = dummyHead.next;
while(cur != null){
if(cur.e.equals(e))
return true;
cur = cur.next;
}
return false;
}
// 从链表中删除index(0-based)位置的元素, 返回删除的元素
// 在链表中不是一个常用的操作,练习用:)
public E remove(int index){
if(index < 0 || index >= size)
throw new IllegalArgumentException("Remove failed. Index is illegal.");
Node prev = dummyHead;
for(int i = 0 ; i < index ; i ++)
prev = prev.next;
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size --;
return retNode.e;
}
// 从链表中删除第一个元素, 返回删除的元素
public E removeFirst(){
return remove(0);
}
// 从链表中删除最后一个元素, 返回删除的元素
public E removeLast(){
return remove(size - 1);
}
// 从链表中删除元素e
public void removeElement(E e){
Node prev = dummyHead;
while(prev.next != null){
if(prev.next.e.equals(e))
break;
prev = prev.next;
}
if(prev.next != null){
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
Node cur = dummyHead.next;
while (cur != null){
res.append(cur.e + "->");
cur = cur.next;
}
res.append("NULL");
return res.toString();
}
}
基于链表的集合的实现
public class LinkedListSet<E> implements Set<E> {
private LinkedList<E> list;
public LinkedListSet() {
list = new LinkedList<>();
}
@Override
public void add(E e) {
if(!list.contains(e)) //判断是否已存在元素e
list.addFirst(e); //在链表头添加元素比较省时间
}
@Override
public void remove(E e) {
list.removeElement(e);
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
@Override
public boolean containes(E e) {
return list.contains(e);
}
@Override
public int getSize() {
return list.getSize();
}
}
时间复杂度对比
| 操作 | LinkedListSet | BSTSet |
|---|---|---|
| 增add | O(n) | O(logn) |
| 删remove | O(n) | O(logn) |
| 查contains | O(n) | O(logn) |
BSTSet的时间复杂度O(logn)的情况是指平均情况,在极端情况下,有可能就是一个链表,这时候的时间复杂度就是O(n).
测试用例
用代码比较两种数据结构的时间,测试类FileOperation,找一个英文电子书进行统计分析,统计其词汇总数和词汇量.
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Locale;
import java.util.Scanner;
public class FileOperation {
//读取文件名称为filename中的内容,并且将其中包含的所有词语放进words中
public static boolean readFiles(String filename,ArrayList<String> words){
if(filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
}
//文件读取
Scanner scanner;
try{
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis),"UTF-8");
scanner.useLocale(Locale.ENGLISH);
}else
return false;
}catch (IOException e){
System.out.println("cannot open "+ filename);
return false;
}
///简单分词
if(scanner.hasNextLine()){
String contents = scanner.useDelimiter("\\A").next();
int start = firstCharacterIndex(contents,0);
for(int i = start + 1; i < contents.length();){
if(i == contents.length() || !Character.isLetter(contents.charAt(i))){
String word = contents.substring(start,i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents,i);
i = start +1;
}else
i++;
}
}
return true;
}
private static int firstCharacterIndex(String s,int start){
for(int i = start;i<s.length();i++){
if(Character.isLetter(s.charAt(i)))
return i;
}
return s.length();
}
}
Main函数:
import java.util.ArrayList;
public class Main {
public static void main(String[] srgs){
System.out.println("Harry");
ArrayList<String> words1 = new ArrayList<>();
FileOperation.readFiles("C:\\Users\\homxu\\Desktop\\Harry Potter and the Sorcerer'_one .mobi",words1);
System.out.println("Total words:"+words1.size());
BSTSet<String> set1 = new BSTSet<>();
for(String word:words1)
set1.add(word);
System.out.println("Dif Words:" + set1.getSize());
ArrayList<String> words2 = new ArrayList<>();
FileOperation.readFiles("C:\\Users\\homxu\\Desktop\\Harry Potter and the Sorcerer'_one .mobi",words2);
System.out.println("Total words:"+words2.size());
LinkedListSet<String> set2 = new LinkedListSet<>();
for(String word:words2){
set2.add(word);
}
System.out.println("Dif Words:" + set2.getSize());
}
}
我的电脑上的运行结果,使用两种底层的数据结构实现的集合类结果是一样的。但是运行过程中明显感觉到BSTSet的速度要比LinkedListSet的速度快 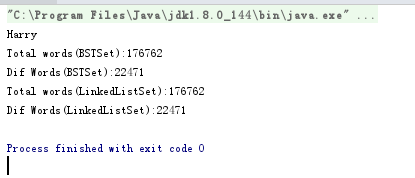
因为集合是不存放重复元素的,所以使用二分搜索树来实现集合很合适。 集合的几个简单方法:
- void add(E) //添加元素,但不能添加重复元素
- void remove(E) //删除元素E
- boolean contains(E) //是否包含元素E
- int getSize() //获得集合的size
- boolean isEmpty() //判断集合是否为空
基于二分搜索树的实现
首先使用二分搜索树做底层实现集合类。二分搜索树的实现代码:https://homxuwang.github.io/2018/07/18/%E4%BA%8C%E5%88%86%E6%90%9C%E7%B4%A2%E6%A0%91/
创建集合接口类Set:
public interface Set<E> {
void add(E e);
void remove(E e);
boolean isEmpty();
boolean containes(E e);
int getSize();
}
然后创建实现集合的类BSTSet:
public class BSTSet<E extends Comparable<E>> implements Set<E> {
private BST<E> bst;
public BSTSet() {
bst = new BST<>();
}
@Override
public void add(E e) {
bst.add(e);
}
@Override
public void remove(E e) {
bst.remove(e);
}
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
@Override
public boolean containes(E e) {
return bst.contains(e);
}
@Override
public int getSize() {
return bst.size();
}
}
其实BSTSet集合类只是简单的调用了其基础类BST类的方法。就可以实现集合类的各个功能。
基于链表的实现
链表结构的实现
首先链表的实现代码:
public class LinkedList<E> {
private class Node{
public E e;
public Node next;
/**
* 构造函数
* @param e
* @param next
*/
public Node(E e,Node next){
this.e = e;
this.next = next;
}
public Node(E e){
this(e,null);
}
public Node(){
this(null,null);
}
@Override
public String toString(){
return e.toString();
}
}
private Node dummyHead;
private int size;
public LinkedList(){
dummyHead = new Node();
size = 0;
}
//返回链表中的元素个数
public int getSize(){
return size;
}
//返回链表是否为空
public boolean isEmpty(){
return size == 0;
}
//在链表头添加新的元素e
public void addFirst(E e){
// Node node = new Node(e);
// node.next = head;
// head = node;
//和上面三行相等
add(0,e);
}
//在链表末尾添加新的元素e
public void addLast(E e){
add(size,e);
}
//在中间位置插入新的元素e
public void add(int index,E e){
if(index < 0 || index > size ){
throw new IllegalArgumentException("illegal index");
}
Node prev = dummyHead;
for(int i = 0 ; i < index ; i++){
prev = prev.next;
}
Node node = new Node(e);
node.next = prev.next;
prev.next = node;
size ++;
}
//获得链表中index位置的元素
public E get(int index){
if(index < 0 || index >= size ){
throw new IllegalArgumentException("Get failed.Illegal index.");
}
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i++){
cur = cur.next;
}
return cur.e;
}
//获得链表的第一个元素
public E getFirst(){
return get(0);
}
//获得链表的最后一个元素
public E getLast(){
return get(size - 1);
}
//修改链表index位置的元素为e
public void set(int index,E e){
if(index < 0 || index >= size ){
throw new IllegalArgumentException("Set failed.Illegal index.");
}
Node cur = dummyHead.next;
for(int i = 0 ; i < index ; i++ ){
cur = cur.next;
}
cur.e = e;
}
//检查链表中是否有元素e
public boolean contains(E e){
Node cur = dummyHead.next;
while(cur != null){
if(cur.e.equals(e))
return true;
cur = cur.next;
}
return false;
}
// 从链表中删除index(0-based)位置的元素, 返回删除的元素
// 在链表中不是一个常用的操作,练习用:)
public E remove(int index){
if(index < 0 || index >= size)
throw new IllegalArgumentException("Remove failed. Index is illegal.");
Node prev = dummyHead;
for(int i = 0 ; i < index ; i ++)
prev = prev.next;
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size --;
return retNode.e;
}
// 从链表中删除第一个元素, 返回删除的元素
public E removeFirst(){
return remove(0);
}
// 从链表中删除最后一个元素, 返回删除的元素
public E removeLast(){
return remove(size - 1);
}
// 从链表中删除元素e
public void removeElement(E e){
Node prev = dummyHead;
while(prev.next != null){
if(prev.next.e.equals(e))
break;
prev = prev.next;
}
if(prev.next != null){
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
Node cur = dummyHead.next;
while (cur != null){
res.append(cur.e + "->");
cur = cur.next;
}
res.append("NULL");
return res.toString();
}
}
基于链表的集合的实现
public class LinkedListSet<E> implements Set<E> {
private LinkedList<E> list;
public LinkedListSet() {
list = new LinkedList<>();
}
@Override
public void add(E e) {
if(!list.contains(e)) //判断是否已存在元素e
list.addFirst(e); //在链表头添加元素比较省时间
}
@Override
public void remove(E e) {
list.removeElement(e);
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
@Override
public boolean containes(E e) {
return list.contains(e);
}
@Override
public int getSize() {
return list.getSize();
}
}
时间复杂度对比
| 操作 | LinkedListSet | BSTSet |
|---|---|---|
| 增add | O(n) | O(logn) |
| 删remove | O(n) | O(logn) |
| 查contains | O(n) | O(logn) |
BSTSet的时间复杂度O(logn)的情况是指平均情况,在极端情况下,有可能就是一个链表,这时候的时间复杂度就是O(n).
测试用例
用代码比较两种数据结构的时间,测试类FileOperation,找一个英文电子书进行统计分析,统计其词汇总数和词汇量.
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Locale;
import java.util.Scanner;
public class FileOperation {
//读取文件名称为filename中的内容,并且将其中包含的所有词语放进words中
public static boolean readFiles(String filename,ArrayList<String> words){
if(filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
}
//文件读取
Scanner scanner;
try{
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis),"UTF-8");
scanner.useLocale(Locale.ENGLISH);
}else
return false;
}catch (IOException e){
System.out.println("cannot open "+ filename);
return false;
}
///简单分词
if(scanner.hasNextLine()){
String contents = scanner.useDelimiter("\\A").next();
int start = firstCharacterIndex(contents,0);
for(int i = start + 1; i < contents.length();){
if(i == contents.length() || !Character.isLetter(contents.charAt(i))){
String word = contents.substring(start,i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents,i);
i = start +1;
}else
i++;
}
}
return true;
}
private static int firstCharacterIndex(String s,int start){
for(int i = start;i<s.length();i++){
if(Character.isLetter(s.charAt(i)))
return i;
}
return s.length();
}
}
Main函数:
import java.util.ArrayList;
public class Main {
public static void main(String[] srgs){
System.out.println("Harry");
ArrayList<String> words1 = new ArrayList<>();
FileOperation.readFiles("C:\\Users\\homxu\\Desktop\\Harry Potter and the Sorcerer'_one .mobi",words1);
System.out.println("Total words:"+words1.size());
BSTSet<String> set1 = new BSTSet<>();
for(String word:words1)
set1.add(word);
System.out.println("Dif Words:" + set1.getSize());
ArrayList<String> words2 = new ArrayList<>();
FileOperation.readFiles("C:\\Users\\homxu\\Desktop\\Harry Potter and the Sorcerer'_one .mobi",words2);
System.out.println("Total words:"+words2.size());
LinkedListSet<String> set2 = new LinkedListSet<>();
for(String word:words2){
set2.add(word);
}
System.out.println("Dif Words:" + set2.getSize());
}
}
我的电脑上的运行结果,使用两种底层的数据结构实现的集合类结果是一样的。但是运行过程中明显感觉到BSTSet的速度要比LinkedListSet的速度快