用户日志统计分析
离线数据处理架构
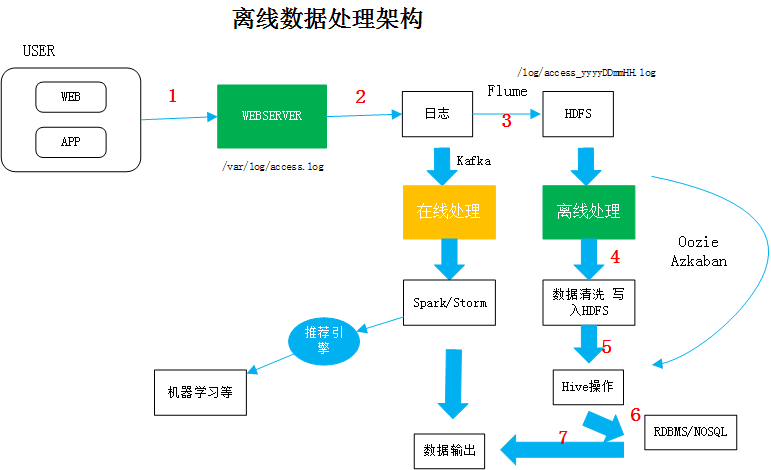
- 用户通过APP或者PC访问服务器
- 这期间的操作日志信息用nginx记录下来(如记录在/var/log/access.log),记录在nginx服务器
- 借助Flume框架,将日志信息抽取到HDFS中(命名规则根据自己的需要进行修改)
- 离线数据处理的第一步就是清理脏数据,清理完脏数据后继续写入HDFS
- 继续进行Hive(这里的Hive是一个统称,如Spark Sql)
- 处理完的结果写入RDBMS中或者NO SQL中
- 进行相应的数据输出(如表格,图形化输出)
离线处理的作业过程可以使用任务调度框架(Oozie或Azkaban)进行任务调度,安排每天进行作业的时间。可以将4.5.步骤串联起来
Kafka可以将日志进行实时处理,数据来了后进行立即处理(这是实时流处理)
本篇是写离线处理的一些代码分析和实现。
首先看数据(数据来自粉丝日志的教程,地址:http://blog.fens.me/hadoop-mapreduce-log-kpi/):
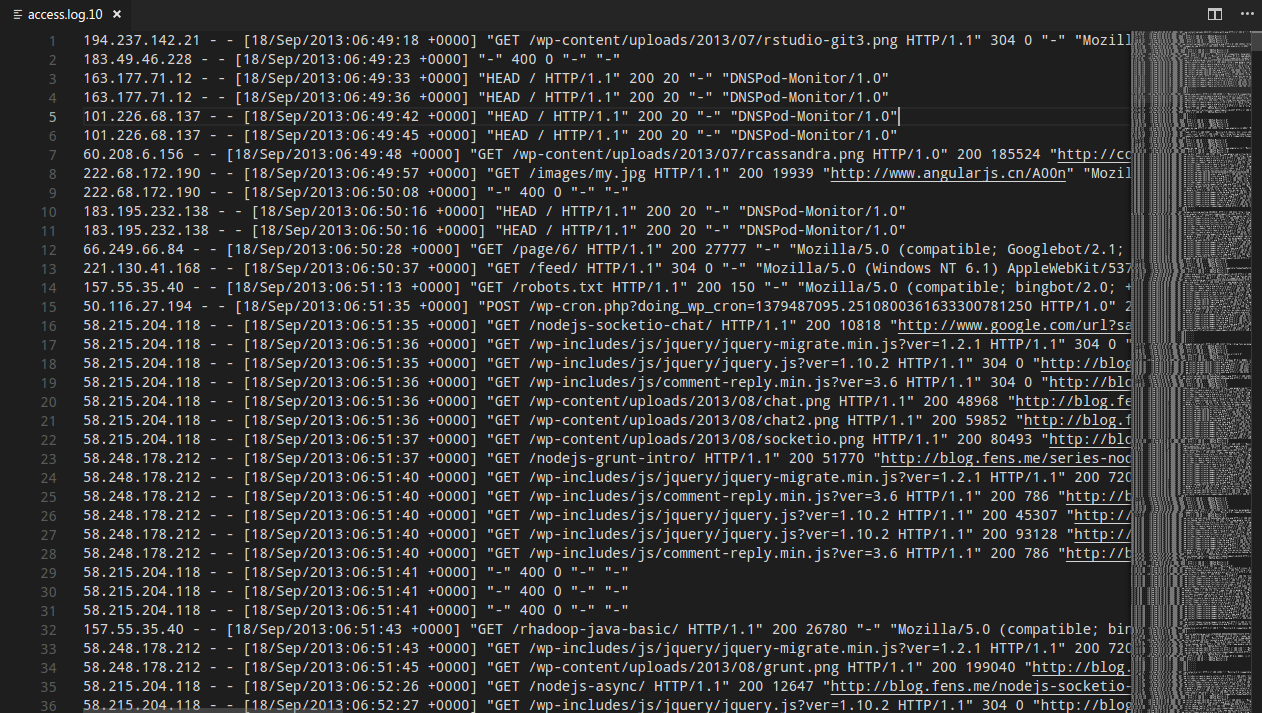
摘取某一行的内容如下:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
remote_addr: 记录客户端的ip地址, 222.68.172.190
remote_user: 记录客户端用户名称, –
time_local: 记录访问时间与时区, [18/Sep/2013:06:49:57 +0000]
request: 记录请求的url与http协议, “GET /images/my.jpg HTTP/1.1”
status: 记录请求状态,成功是200, 200
body_bytes_sent: 记录发送给客户端文件主体内容大小, 19939
http_referer: 用来记录从那个页面链接访问过来的, “http://www.angularjs.cn/A00n”
http_user_agent: 记录客户浏览器的相关信息, “Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36”
目的:
- 根据日志信息抽取出浏览器的信息
- 针对不同的浏览器进行统计
单机版代码分析和实现
新建一个类,进行单机的测试
下载配置userAgentParser工具类
在github上下载工具类:https://github.com/LeeKemp/UserAgentParser
然后在本地用maven进行编译,编译的时候我出现了一些问题,见文章最后的踩坑记。
新建一个单元测试方法: 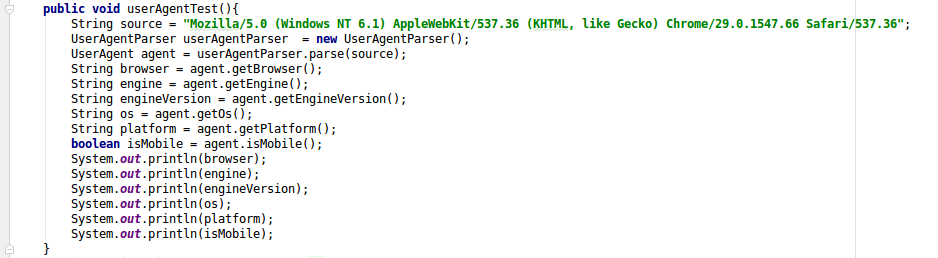 输入一行数据进行测试
输入一行数据进行测试 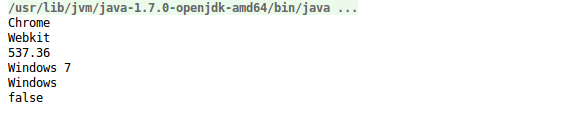
进行日志读取分析,统计访问网站的浏览器的数据
相应的引入的文件: 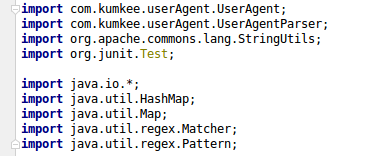
public void readFileTest() throws IOException{
//文件路径
String path = "/home/hadoop/study/data/access.log.10";
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(new File(path)))
);
String line = "";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent ;
Map<String,Integer> broswerMap = new HashMap<String,Integer>();
int i = 0 ;
while(line != null){
line = reader.readLine(); //一次读一行数据
i ++;
if(StringUtils.isNotBlank(line)){//判断是否为空
String source = line.substring(getCharacterPosition(line,"\"",5) + 1);
agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
String engine = agent.getEngine();
String engineVersion = agent.getEngineVersion();
String os = agent.getOs();
String platform = agent.getPlatform();
boolean isMobile = agent.isMobile();
Integer broswerValue = broswerMap.get(browser);
if(broswerMap.get(browser) != null){
broswerMap.put(browser,broswerValue + 1);
}else{
broswerMap.put(browser,1);
}
// System.out.println(browser + "," + engine + " " + engineVersion + " " + os + " " + platform);
}
}
//一共有多少条数据
System.out.println(i-1);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
for(Map.Entry<String,Integer> entry : broswerMap.entrySet()){
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
定义私有方法获取指定字符串中指定标识的字符串出现的索引,分析某一行的用户日志,可以使用"进行分割,获取访问的客户端等信息在第5个",所以operator = ",index = 5
/**
* 获取指定字符串中指定标识的字符串出现的索引
* @return
*/
private int getCharacterPosition(String value,String operator,int index){
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIndex = 0;
while(slashMatcher.find()){
mIndex ++;
if(mIndex == index){
break;
}
}
return slashMatcher.start();
}
可以查看打印结果: 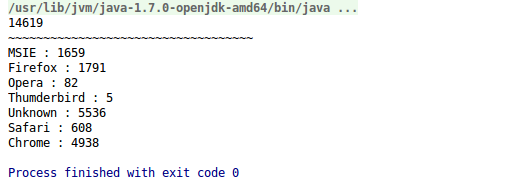
MapReduce实现需求统计
新建类
代码编写
可以参考 MapReduce的补充和WordCount简单实战(二):https://homxuwang.github.io/2018/07/29/MapReduce%E7%9A%84%E8%A1%A5%E5%85%85%E5%92%8CWordCount%E7%AE%80%E5%8D%95%E5%AE%9E%E6%88%982/
package com.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 使用MapReduce 统计浏览器的访问次数
*/
public class LogApp {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
LongWritable plusone = new LongWritable(1);
private UserAgentParser userAgentParser ;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
userAgentParser = new UserAgentParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
UserAgent agent ;
//先读入没一行数据
String line = value.toString();
String source = line.substring(getCharacterPosition(line,"\"",5) + 1);
agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
context.write(new Text(browser),plusone);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser = null;
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0 ;
for(LongWritable value : values){
sum += value.get();//通过get()转化为java中的类型
}
//最终统计结果输出
context.write(key,new LongWritable(sum));
}
}
/**
* 获取指定字符串中指定标识的字符串出现的索引
* @return
*/
private static int getCharacterPosition(String value,String operator,int index){
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIndex = 0;
while(slashMatcher.find()){
mIndex ++;
if(mIndex == index){
break;
}
}
return slashMatcher.start();
}
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException {
Configuration configuration = new Configuration();
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("filePath exists,but it has deleted");
}
Job job = Job.getInstance(configuration,"LogBrowser");
job.setJarByClass(LogApp.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
job.setMapperClass(LogApp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(LogApp.MyReducer.class);
job.setReducerClass(LogApp.MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.out.println(job.waitForCompletion(true)? 0 : 1);
}
}
配置pom.xml文件
在生产环境中hadoop的包是不需要的,所以加一个<scope>provided</scope> 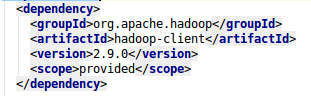
而因为UserAgentParser是第三方的包,在mvn打包的时候需要进行配置才能够添加进去,使用maven-assembly-plugin
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
打包命令使用
mvn assembly:assembly
 可以看到打包成功的信息
可以看到打包成功的信息 
hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar就是打包成功的文件
然后传到指定位置(或者服务器),我这里单机的伪分布式框架,所以传到本地一个目录就可以:
scp hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar ~/lib
然后将日志数据上传到hdfs的根目录: 
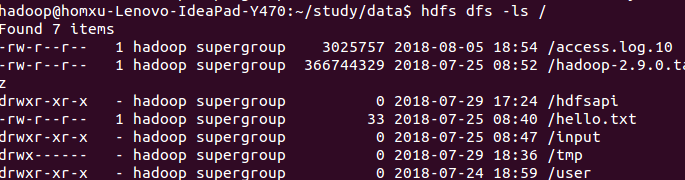
执行命令
hadoop jar /home/hadoop/lib/hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar com.hadoop.project.LogApp hdfs://localhost:9000/access.log.10 hdfs://localhost:9000/Log/logBrowser
可以看到成功信息  在目录中查看:
在目录中查看:  查看结果:
查看结果: 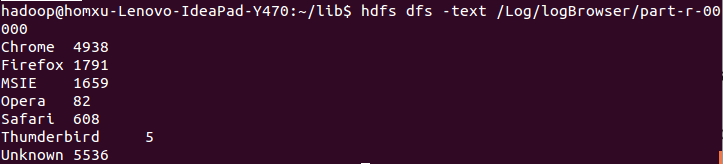 这与在单元测试中看到的信息是一样的:
这与在单元测试中看到的信息是一样的:
下一步可以写到RDBMS中或者NOSQL数据库中,进一步进行可视化展示 这只是单纯的统计了浏览器的记录,在实际应用中,应该根据日志中的时间记录统计每一天或者没一星期的时间周期中的访问记录。
踩到的坑
mvn打包时的错误
在github仓库下载了UserAgentParser工具类后,需要在自己电脑上打包(mvn clean package -DskipTests)。打包过程中报错: 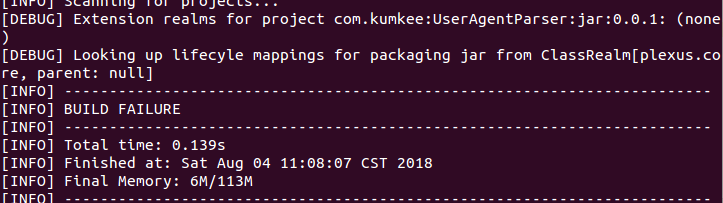 这里报错为
这里报错为(请使用 -source 5 或更高版本以启用泛型)和-source1.3 中不支持泛型.后来发现原来是下载的项目年代过久(已经7年了)。我本地的环境是maven 3.0.5和java 1.7.所以在下载的项目的pom.xml中添加一段代码,用来指定打包的项目所使用的java版本:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
 这样打包就可以了
这样打包就可以了 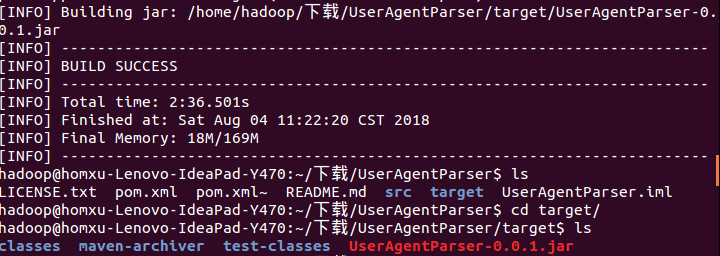
maven引入刚才打包的文件出现的问题
在打包完成后,还需要将打包后的文件放入maven的本地仓库以便使用(mvn clean install -DskipTest).打包完成后的信息: 
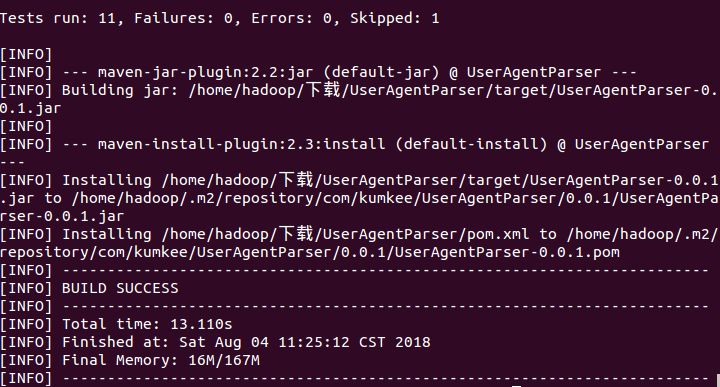
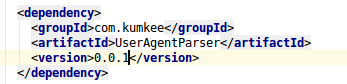
可以看到打包完成后的目录在/home/hadoop/.m2/respository/com/kumkee/下,这个是maven的本地默认仓库目录。 而我在项目中使用的目录是后来指定的目录,所以在引用时一直不行,后来终于找到了这个问题 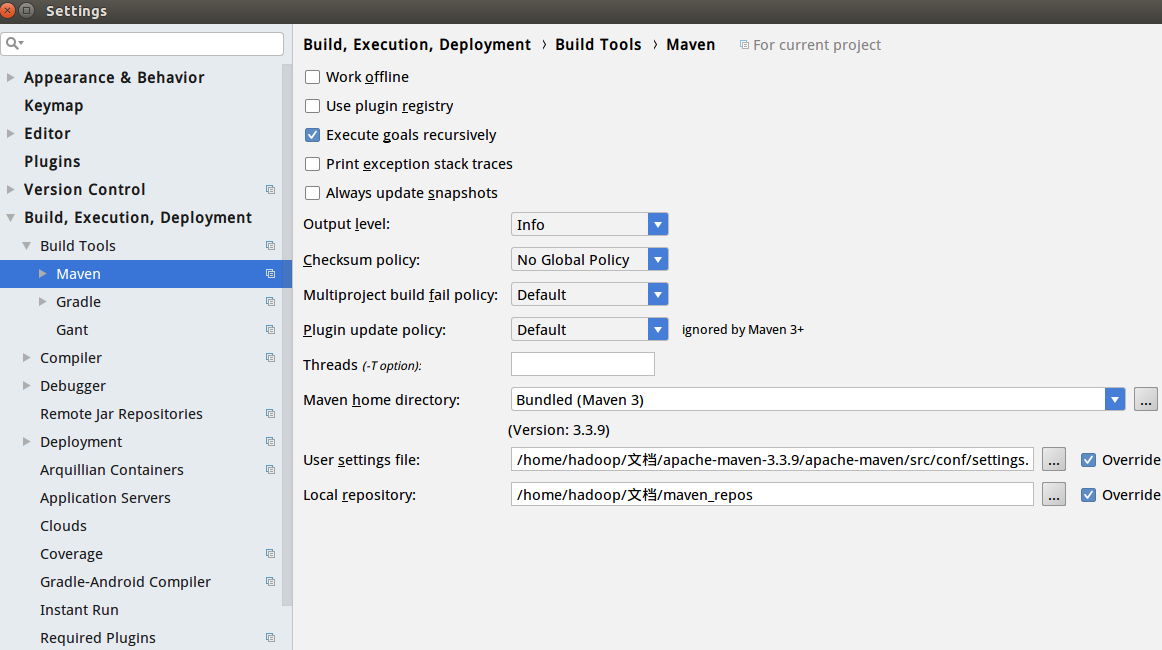
可以看到本地的仓库指定在/home/hadoop/文档/maven_repos,所以在打包的时候可以指定打包到本地的maven目录,即mvn clean install -DskipTest -Dmaven.repo.local=/home/hadoop/文档/maven_repos
这样就可以在项目中引入了
MapReduce作业时报错
错误信息:
TaskAttemptListenerImpl: Task: attempt_1533460421274_0001_m_000000_0 - exited : java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.LongWritable, received org.apache.hadoop.io.Text
原来是写成了两个job.setMapOutpuKeyClass()方法,改正后重新编译jar包并运行即可 
离线数据处理架构
- 用户通过APP或者PC访问服务器
- 这期间的操作日志信息用nginx记录下来(如记录在/var/log/access.log),记录在nginx服务器
- 借助Flume框架,将日志信息抽取到HDFS中(命名规则根据自己的需要进行修改)
- 离线数据处理的第一步就是清理脏数据,清理完脏数据后继续写入HDFS
- 继续进行Hive(这里的Hive是一个统称,如Spark Sql)
- 处理完的结果写入RDBMS中或者NO SQL中
- 进行相应的数据输出(如表格,图形化输出)
离线处理的作业过程可以使用任务调度框架(Oozie或Azkaban)进行任务调度,安排每天进行作业的时间。可以将4.5.步骤串联起来
Kafka可以将日志进行实时处理,数据来了后进行立即处理(这是实时流处理)
本篇是写离线处理的一些代码分析和实现。
首先看数据(数据来自粉丝日志的教程,地址:http://blog.fens.me/hadoop-mapreduce-log-kpi/):
摘取某一行的内容如下:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
remote_addr: 记录客户端的ip地址, 222.68.172.190
remote_user: 记录客户端用户名称, –
time_local: 记录访问时间与时区, [18/Sep/2013:06:49:57 +0000]
request: 记录请求的url与http协议, “GET /images/my.jpg HTTP/1.1”
status: 记录请求状态,成功是200, 200
body_bytes_sent: 记录发送给客户端文件主体内容大小, 19939
http_referer: 用来记录从那个页面链接访问过来的, “http://www.angularjs.cn/A00n”
http_user_agent: 记录客户浏览器的相关信息, “Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36”
目的:
- 根据日志信息抽取出浏览器的信息
- 针对不同的浏览器进行统计
单机版代码分析和实现
新建一个类,进行单机的测试
下载配置userAgentParser工具类
在github上下载工具类:https://github.com/LeeKemp/UserAgentParser
然后在本地用maven进行编译,编译的时候我出现了一些问题,见文章最后的踩坑记。
新建一个单元测试方法: 输入一行数据进行测试
进行日志读取分析,统计访问网站的浏览器的数据
相应的引入的文件:
public void readFileTest() throws IOException{
//文件路径
String path = "/home/hadoop/study/data/access.log.10";
BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(new File(path)))
);
String line = "";
UserAgentParser userAgentParser = new UserAgentParser();
UserAgent agent ;
Map<String,Integer> broswerMap = new HashMap<String,Integer>();
int i = 0 ;
while(line != null){
line = reader.readLine(); //一次读一行数据
i ++;
if(StringUtils.isNotBlank(line)){//判断是否为空
String source = line.substring(getCharacterPosition(line,"\"",5) + 1);
agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
String engine = agent.getEngine();
String engineVersion = agent.getEngineVersion();
String os = agent.getOs();
String platform = agent.getPlatform();
boolean isMobile = agent.isMobile();
Integer broswerValue = broswerMap.get(browser);
if(broswerMap.get(browser) != null){
broswerMap.put(browser,broswerValue + 1);
}else{
broswerMap.put(browser,1);
}
// System.out.println(browser + "," + engine + " " + engineVersion + " " + os + " " + platform);
}
}
//一共有多少条数据
System.out.println(i-1);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~");
for(Map.Entry<String,Integer> entry : broswerMap.entrySet()){
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
定义私有方法获取指定字符串中指定标识的字符串出现的索引,分析某一行的用户日志,可以使用"进行分割,获取访问的客户端等信息在第5个",所以operator = ",index = 5
/**
* 获取指定字符串中指定标识的字符串出现的索引
* @return
*/
private int getCharacterPosition(String value,String operator,int index){
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIndex = 0;
while(slashMatcher.find()){
mIndex ++;
if(mIndex == index){
break;
}
}
return slashMatcher.start();
}
可以查看打印结果:
MapReduce实现需求统计
新建类
代码编写
可以参考 MapReduce的补充和WordCount简单实战(二):https://homxuwang.github.io/2018/07/29/MapReduce%E7%9A%84%E8%A1%A5%E5%85%85%E5%92%8CWordCount%E7%AE%80%E5%8D%95%E5%AE%9E%E6%88%982/
package com.hadoop.project;
import com.kumkee.userAgent.UserAgent;
import com.kumkee.userAgent.UserAgentParser;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 使用MapReduce 统计浏览器的访问次数
*/
public class LogApp {
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
LongWritable plusone = new LongWritable(1);
private UserAgentParser userAgentParser ;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
userAgentParser = new UserAgentParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
UserAgent agent ;
//先读入没一行数据
String line = value.toString();
String source = line.substring(getCharacterPosition(line,"\"",5) + 1);
agent = userAgentParser.parse(source);
String browser = agent.getBrowser();
context.write(new Text(browser),plusone);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
userAgentParser = null;
}
}
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0 ;
for(LongWritable value : values){
sum += value.get();//通过get()转化为java中的类型
}
//最终统计结果输出
context.write(key,new LongWritable(sum));
}
}
/**
* 获取指定字符串中指定标识的字符串出现的索引
* @return
*/
private static int getCharacterPosition(String value,String operator,int index){
Matcher slashMatcher = Pattern.compile(operator).matcher(value);
int mIndex = 0;
while(slashMatcher.find()){
mIndex ++;
if(mIndex == index){
break;
}
}
return slashMatcher.start();
}
public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException {
Configuration configuration = new Configuration();
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath,true);
System.out.println("filePath exists,but it has deleted");
}
Job job = Job.getInstance(configuration,"LogBrowser");
job.setJarByClass(LogApp.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
job.setMapperClass(LogApp.MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setCombinerClass(LogApp.MyReducer.class);
job.setReducerClass(LogApp.MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.out.println(job.waitForCompletion(true)? 0 : 1);
}
}
配置pom.xml文件
在生产环境中hadoop的包是不需要的,所以加一个<scope>provided</scope>
而因为UserAgentParser是第三方的包,在mvn打包的时候需要进行配置才能够添加进去,使用maven-assembly-plugin
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
打包命令使用
mvn assembly:assembly
可以看到打包成功的信息 hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar就是打包成功的文件
然后传到指定位置(或者服务器),我这里单机的伪分布式框架,所以传到本地一个目录就可以:
scp hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar ~/lib
然后将日志数据上传到hdfs的根目录:
执行命令
hadoop jar /home/hadoop/lib/hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar com.hadoop.project.LogApp hdfs://localhost:9000/access.log.10 hdfs://localhost:9000/Log/logBrowser
可以看到成功信息 在目录中查看: 查看结果: 这与在单元测试中看到的信息是一样的:
下一步可以写到RDBMS中或者NOSQL数据库中,进一步进行可视化展示 这只是单纯的统计了浏览器的记录,在实际应用中,应该根据日志中的时间记录统计每一天或者没一星期的时间周期中的访问记录。
踩到的坑
mvn打包时的错误
在github仓库下载了UserAgentParser工具类后,需要在自己电脑上打包(mvn clean package -DskipTests)。打包过程中报错: 这里报错为(请使用 -source 5 或更高版本以启用泛型)和-source1.3 中不支持泛型.后来发现原来是下载的项目年代过久(已经7年了)。我本地的环境是maven 3.0.5和java 1.7.所以在下载的项目的pom.xml中添加一段代码,用来指定打包的项目所使用的java版本:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
这样打包就可以了
maven引入刚才打包的文件出现的问题
在打包完成后,还需要将打包后的文件放入maven的本地仓库以便使用(mvn clean install -DskipTest).打包完成后的信息:
可以看到打包完成后的目录在/home/hadoop/.m2/respository/com/kumkee/下,这个是maven的本地默认仓库目录。 而我在项目中使用的目录是后来指定的目录,所以在引用时一直不行,后来终于找到了这个问题
可以看到本地的仓库指定在/home/hadoop/文档/maven_repos,所以在打包的时候可以指定打包到本地的maven目录,即mvn clean install -DskipTest -Dmaven.repo.local=/home/hadoop/文档/maven_repos
这样就可以在项目中引入了
MapReduce作业时报错
错误信息:
TaskAttemptListenerImpl: Task: attempt_1533460421274_0001_m_000000_0 - exited : java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.LongWritable, received org.apache.hadoop.io.Text
原来是写成了两个job.setMapOutpuKeyClass()方法,改正后重新编译jar包并运行即可