MapReduce的补充和WordCount简单实战(一)
官网介绍:http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
首先回顾一些MapReduce的基础知识: https://homxuwang.github.io/2018/04/24/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%9F%BA%E7%A1%80%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%EF%BC%88%E5%85%AD%EF%BC%89%E2%80%94%E2%80%94MapReduce/
- Hadoop MapReduce是Google MapReduce的实现
- MapReduce的优点: 海量数据离线处理 易开发(JAVA API) 易运行
- MapReduce的缺点: 实时流式计算(MR是根据请求服务的方式进行计算;多个应用程序存在依赖关系,MR的作业,数据需要落地到HDFS或者磁盘。所以不能实现实时流式计算)
MapReduce的执行过程
参考:https://www.cnblogs.com/ahu-lichang/p/6645074.html
官网的介绍:
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
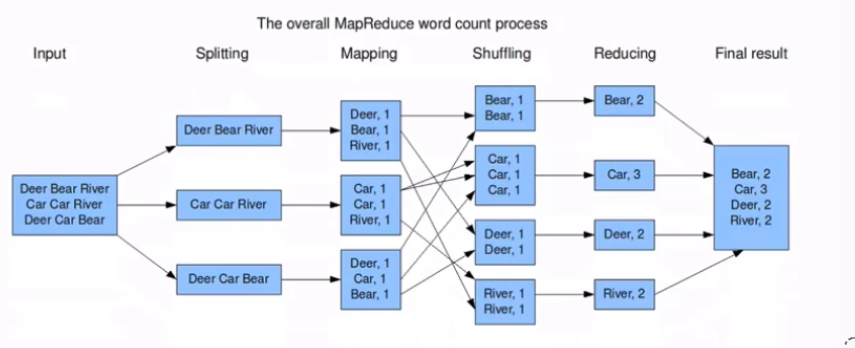
- Input –> Spliting 一个文件被分成很多个块(默认情况下一个split对应HDFS中的一个block,用户可以进行修改)
- Spliting –> Mapping 一个块交由一个Map任务处理,处理完的结果写到本地
- Mapping –> Shuffling –> Reducing写到本地的文件通过Shuffle后进行传输,把相同的key写到一个Reduce中,在Reduce中进行统计
- Reducing统计的结果最终写到文件系统上
看看官网的解释:
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
关于Writable接口
在上面的介绍中看到,key和value需要实现Writable接口,并且key还需要实现WritableComparable接口
这个接口需要反复阅读
关于Writable接口的介绍:http://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html
关于WritableComparable接口的介绍: http://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/WritableComparable.html
在Writable接口中主要实现write和readFields方法。
再看上文面的wordcount的图和(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)这个过程:
其中k1就是偏移量。第一行的第一个字符从0开始,v1就是这一行的数据Deer Bear River。那么第二行的偏移量就是第一行的字符的长度相加,值就是Car Car River。以此类推
经过一层转换k2就是上面每一行的单词,每个单词相当于是从v1中拆分出来(Split(“ “)),是一个Text类型,每个单词就是一个1。v2就是一个IntWritable或 LongWritable类型。
reduce输出的就是每个单词输出的总和。k3就是每个单词,v3就是单词出现的总和。
JAVA API的简单介绍
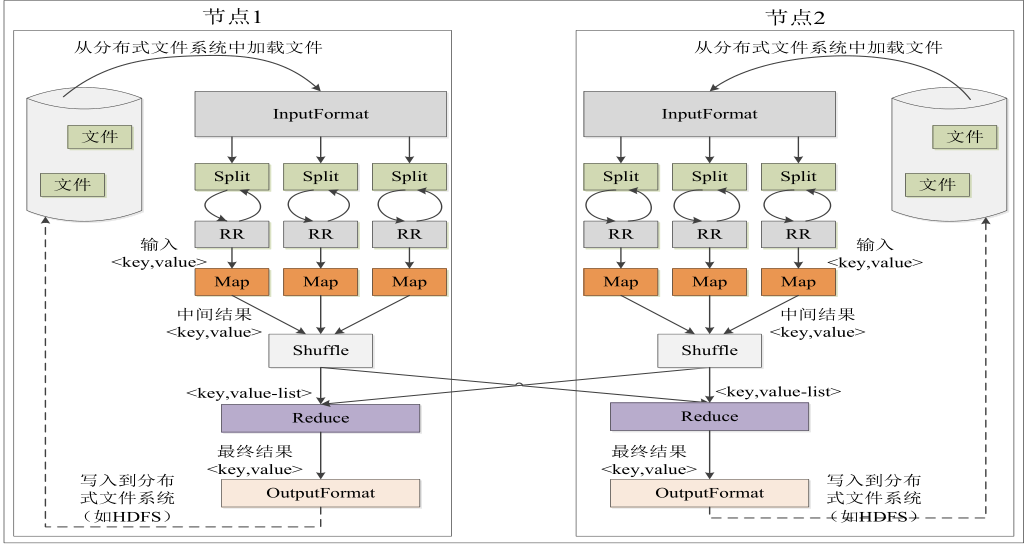
- 看上图,首先读取文件使用
InputFormat类,它是一个接口,在源码中描述为InputFormatdescribes the input-specification for a Map-Reduce job.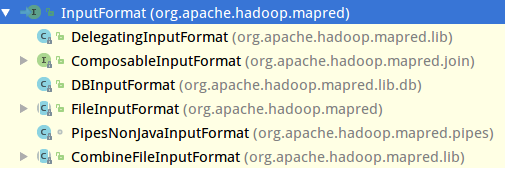
InputFormat的实现类中,用的比较多的是FileInputFormat类.这是一个读取文件系统的基本的类.但是FileInputFormat类仍然是个抽象类。 那么继续找它的子类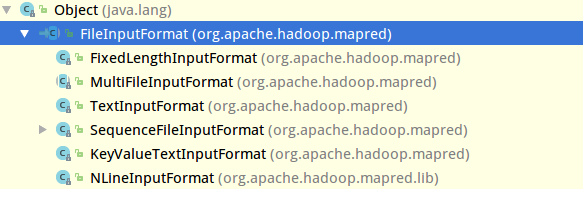 可以看到
可以看到TextInputFormat类.这时候它就是一个实现的类了

官方文档的介绍:
An {@link InputFormat} for plain text files. Files are broken into lines. Either linefeed or carriage-return are used to signal end of line. Keys are the position in the file, and values are the line of text..
其中InputFormat中有几个关键的方法:
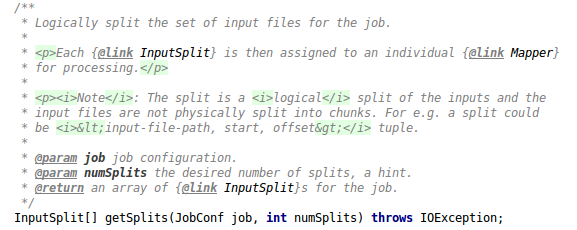
1) InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; 即将一个输入文件分成很多Split,每一个Split交给一个MapTask处理的方法。它的返回值是一个数组,可见一个输入文件可能会的到好几个InputSplit
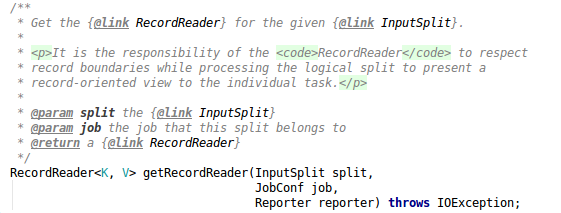
2) RecordReader<K, V> getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException; 它是一个记录读取的方法,从参数可以看到,它从InputSplit[]数组中读进数据,可以知道每一行的数据是什么。
在InputFormat读进数据后(对于文本就是使用TextInputFormat),从图中可以看出,被拆分成好多个Split。拿到Split后,使用RR(RecordReader)把每个Split中的数据读取出来,一行一行的读,每读一行,交由一个map处理.Partitioner将相同的key交到同一个Reduce上,从图中可以看出,key可能会被发送到node1或者node2.中间有一个shuffle的过程,结果交由reduce处理。处理完的结果交给OutputFormat。
OutputFormat
OutputFormatdescribes the output-specification for a Map-Reduce job.
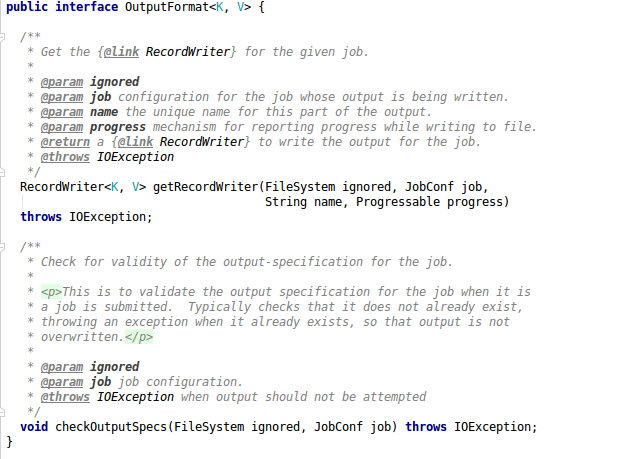
其中getRecordWriter方法就对应InputFormat的getRecordReader方法
继续寻找它的实现类->FileOutputFormat->TextOutputFormat
An {@link OutputFormat} that writes plain text files. 将数据以文本的方式写出去
几个核心概念
-
SplitSplit是交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元 HDFS:blocksize是HDFS中最小的存储单元 128M(或者自己设定) 默认情况下:它们两个一一对应(也可以手动设置) -
InputFormatInputFormat将输入数据进行分片(split):InputSplit[] getSplits(JobConf job, int numSplits) throws IOException默认实用比较多的是TextInputFormat,处理文本格式的数据 -
OutputFormat和InputFormat对应 -
Combiner -
Partitioner
在通过一张图对以上内容进行梳理: 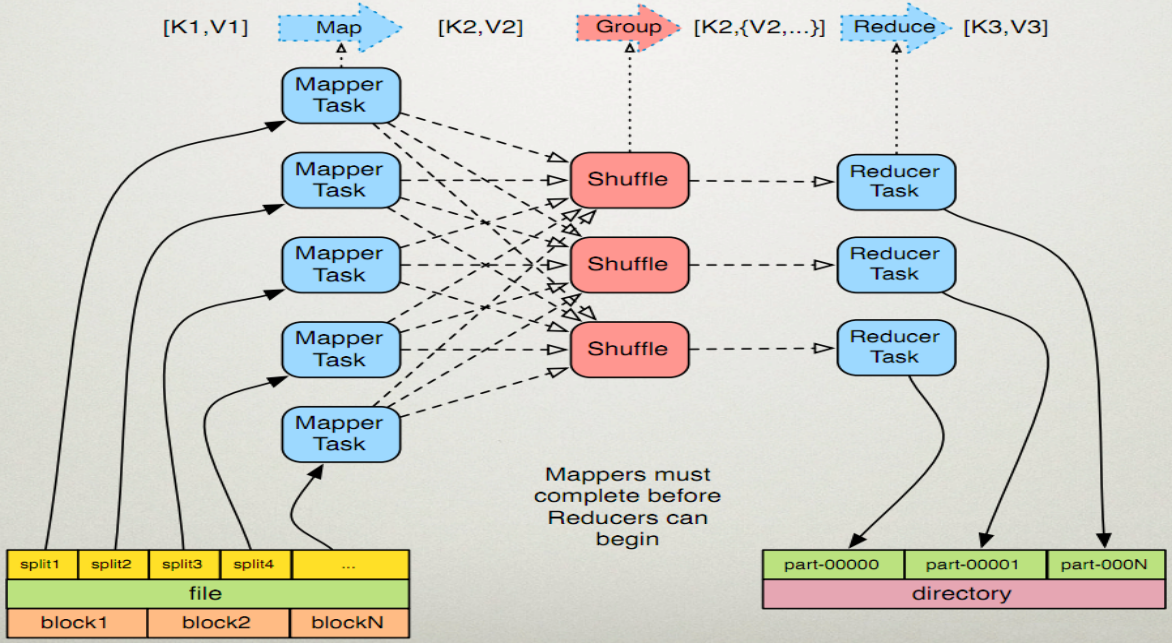
MapReduce架构
MapReduce1.x架构
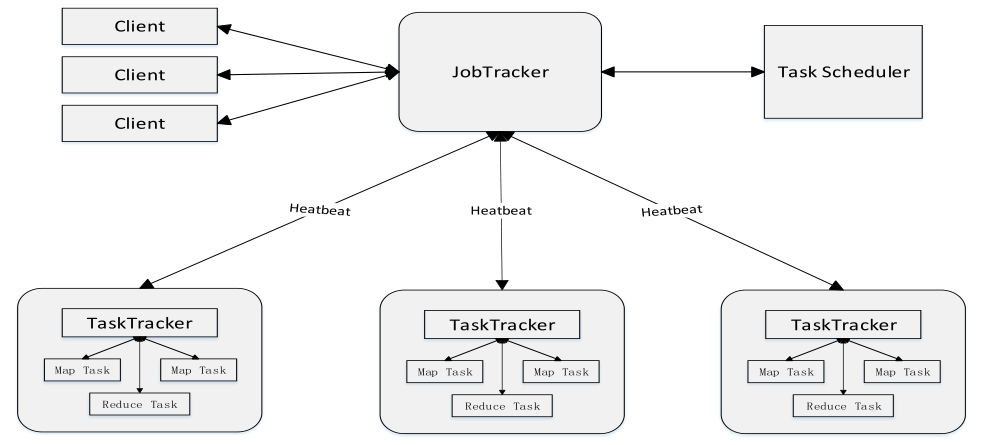
1) JobTracker:JT 作业的管理者 将作业分解成一堆任务:Task(包括MapTask和ReduceTask) 将任务分派给TaskTracker运行 作业的监控、容错处理(task作业挂了,重启task) 在一定时间间隔内,JT没有收到TT的心跳信息,则将任务分配到其他TT上执行 2) TaskTracker:TT 任务的执行者 在TT上执行Task(MapTask和ReduceTask) 会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT 3) MapTask 自己开发的map任务交由该Task来处理 解析每条记录的数据,交给自己的map方法处理 将map的输出结果写到本地磁盘(有些作业只有Map,则写到HDFS) 4) ReduceTadk 将MapTask输出的数据进行读取 按照数据进行分组传给自己编写的reduce方法处理 处理结果输出
MapReduce2.x架构
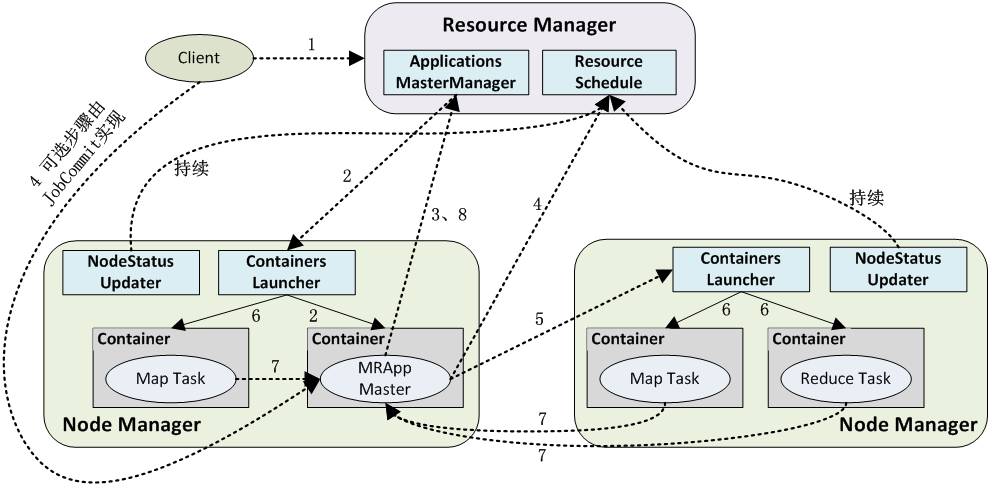
和yarn中的流程类似,MapReduce可以在YARN上跑。
下一篇实战。
官网介绍:http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
首先回顾一些MapReduce的基础知识: https://homxuwang.github.io/2018/04/24/%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%9F%BA%E7%A1%80%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%EF%BC%88%E5%85%AD%EF%BC%89%E2%80%94%E2%80%94MapReduce/
- Hadoop MapReduce是Google MapReduce的实现
- MapReduce的优点: 海量数据离线处理 易开发(JAVA API) 易运行
- MapReduce的缺点: 实时流式计算(MR是根据请求服务的方式进行计算;多个应用程序存在依赖关系,MR的作业,数据需要落地到HDFS或者磁盘。所以不能实现实时流式计算)
MapReduce的执行过程
参考:https://www.cnblogs.com/ahu-lichang/p/6645074.html
官网的介绍:
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
- Input –> Spliting 一个文件被分成很多个块(默认情况下一个split对应HDFS中的一个block,用户可以进行修改)
- Spliting –> Mapping 一个块交由一个Map任务处理,处理完的结果写到本地
- Mapping –> Shuffling –> Reducing写到本地的文件通过Shuffle后进行传输,把相同的key写到一个Reduce中,在Reduce中进行统计
- Reducing统计的结果最终写到文件系统上
看看官网的解释:
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
关于Writable接口
在上面的介绍中看到,key和value需要实现Writable接口,并且key还需要实现WritableComparable接口
这个接口需要反复阅读
关于Writable接口的介绍:http://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/Writable.html
关于WritableComparable接口的介绍: http://hadoop.apache.org/docs/current/api/org/apache/hadoop/io/WritableComparable.html
在Writable接口中主要实现write和readFields方法。
再看上文面的wordcount的图和(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)这个过程:
其中k1就是偏移量。第一行的第一个字符从0开始,v1就是这一行的数据Deer Bear River。那么第二行的偏移量就是第一行的字符的长度相加,值就是Car Car River。以此类推
经过一层转换k2就是上面每一行的单词,每个单词相当于是从v1中拆分出来(Split(“ “)),是一个Text类型,每个单词就是一个1。v2就是一个IntWritable或 LongWritable类型。
reduce输出的就是每个单词输出的总和。k3就是每个单词,v3就是单词出现的总和。
JAVA API的简单介绍
- 看上图,首先读取文件使用
InputFormat类,它是一个接口,在源码中描述为InputFormatdescribes the input-specification for a Map-Reduce job. InputFormat的实现类中,用的比较多的是FileInputFormat类.这是一个读取文件系统的基本的类.但是FileInputFormat类仍然是个抽象类。 那么继续找它的子类 可以看到TextInputFormat类.这时候它就是一个实现的类了
官方文档的介绍:
An {@link InputFormat} for plain text files. Files are broken into lines. Either linefeed or carriage-return are used to signal end of line. Keys are the position in the file, and values are the line of text..
其中InputFormat中有几个关键的方法:
1) InputSplit[] getSplits(JobConf job, int numSplits) throws IOException; 即将一个输入文件分成很多Split,每一个Split交给一个MapTask处理的方法。它的返回值是一个数组,可见一个输入文件可能会的到好几个InputSplit
2) RecordReader<K, V> getRecordReader(InputSplit split,JobConf job,Reporter reporter) throws IOException; 它是一个记录读取的方法,从参数可以看到,它从InputSplit[]数组中读进数据,可以知道每一行的数据是什么。
在InputFormat读进数据后(对于文本就是使用TextInputFormat),从图中可以看出,被拆分成好多个Split。拿到Split后,使用RR(RecordReader)把每个Split中的数据读取出来,一行一行的读,每读一行,交由一个map处理.Partitioner将相同的key交到同一个Reduce上,从图中可以看出,key可能会被发送到node1或者node2.中间有一个shuffle的过程,结果交由reduce处理。处理完的结果交给OutputFormat。
OutputFormat
OutputFormatdescribes the output-specification for a Map-Reduce job.
其中getRecordWriter方法就对应InputFormat的getRecordReader方法
继续寻找它的实现类->FileOutputFormat->TextOutputFormat
An {@link OutputFormat} that writes plain text files. 将数据以文本的方式写出去
几个核心概念
-
SplitSplit是交由MapReduce作业来处理的数据块,是MapReduce中最小的计算单元 HDFS:blocksize是HDFS中最小的存储单元 128M(或者自己设定) 默认情况下:它们两个一一对应(也可以手动设置) -
InputFormatInputFormat将输入数据进行分片(split):InputSplit[] getSplits(JobConf job, int numSplits) throws IOException默认实用比较多的是TextInputFormat,处理文本格式的数据 -
OutputFormat和InputFormat对应 -
Combiner -
Partitioner
在通过一张图对以上内容进行梳理:
MapReduce架构
MapReduce1.x架构
1) JobTracker:JT 作业的管理者 将作业分解成一堆任务:Task(包括MapTask和ReduceTask) 将任务分派给TaskTracker运行 作业的监控、容错处理(task作业挂了,重启task) 在一定时间间隔内,JT没有收到TT的心跳信息,则将任务分配到其他TT上执行 2) TaskTracker:TT 任务的执行者 在TT上执行Task(MapTask和ReduceTask) 会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT 3) MapTask 自己开发的map任务交由该Task来处理 解析每条记录的数据,交给自己的map方法处理 将map的输出结果写到本地磁盘(有些作业只有Map,则写到HDFS) 4) ReduceTadk 将MapTask输出的数据进行读取 按照数据进行分组传给自己编写的reduce方法处理 处理结果输出
MapReduce2.x架构
和yarn中的流程类似,MapReduce可以在YARN上跑。
下一篇实战。